How We Built Anomaly Detection
The anomaly detection module is composed of three core elements: time series, training model, and anomaly detection. These three elements are bound by case logic. A case is a set of specifications for detecting anomalies in a specific context. For each case, time series, training model, and detection tables are built and then aggregated into one reporting table. Time series are used both to build the model and to score new data. ARIMA outputs are consolidated into the reporting table to surface detected anomalies. Time series histories are also added to the reporting table to provide context for each anomaly detected. The time series → training → anomaly detection pattern is native to BigQuery ARIMA. The case logic is specific to GA4Dataform.
Time series
A time series is a unique combination of dimension values available for each data point. If you have a dataset that includes hostname, device, and event name, you will have a time series for each unique combination of those three dimensions. You need to make sure that each time series used in the model has a minimum number of data points and sufficient volume for ARIMA to be effective.
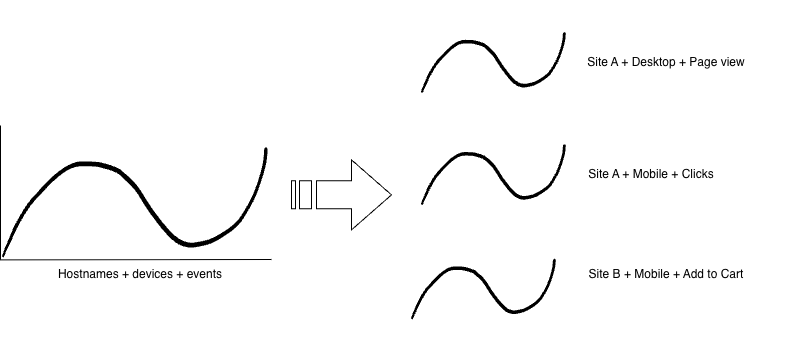
A training dataset is created for each time series, and detection is also run on each time series.
Training and detecting
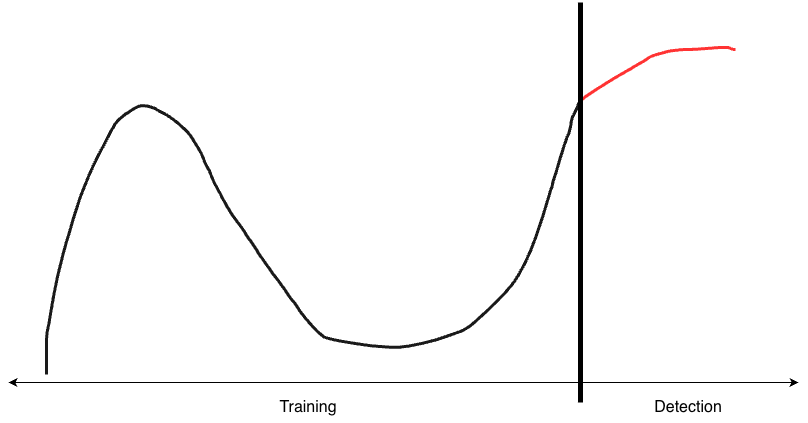
Time series are used both to build the model and to run detection. Historical time series are used to train a model, which is then compared against new time series for detection. You can use a training dataset that is contiguous with your scoring data — for example, yesterday scored against a model trained on the previous three months — but you can also use a different reference period, such as yesterday scored against a model trained on data from the previous year. Building the correct time series for training and then for detection is central to the anomaly detection module. Without a proper training dataset, your anomaly detection will not be effective. Time series should be present in both the training and scoring datasets. If a series is absent from one or the other, you need to know so you can take the appropriate action.
Cases
Each anomaly detection system has its own specificities based on its context. Here are the specificities we wanted to address for web analytics.
Granularity is a challenge because it introduces a wide range of volumes across time series. You end up detecting anomalies for events with anywhere from 50 to 10,000 data points per day. In analytics particularly, this is a challenge: you cannot ignore a purchase event time series even if its volume is lower than that of page views. With page views specifically, drilling down becomes mandatory. You can have an overall 10% decrease in total page views, but if within that group a single hostname accounts for a 90% drop, you need to detect anomalies at that level of granularity. ML.DETECT_ANOMALIES does not perform single-dimension anomaly detection; it operates at the multi-dimension level only. That is why single-dimension detection is also useful.
A case is a set of circumstances or conditions that require specific attention or consideration. Depending on your objectives, operating context, and resources, customers will have different expectations around anomaly detection. The module is not only customisable, cases make it extremely versatile, allowing detection at a very granular level or at a broad, aggregate level. Each time series, training model, and scoring result is reported through each case and consolidated into a unified reporting table. The module also allows you to choose a frozen reference at a specific point in time or a rolling comparison. This lets you use a predetermined, fixed set of reference data when needed.